

Preemptive Run-To-Completion (Non-Blocking) Kernel. More...
Files | |
| file | qk.hpp |
| QK/C++ platform-independent public interface. | |
| file | qpcpp.h |
| QP/C++ public interface old-version for backwards-compatibility. | |
| file | qpcpp.hpp |
| QP/C++ public interface including backwards-compatibility layer. | |
| file | qk.cpp |
| QK/C++ preemptive kernel core functions. | |
| file | qk/qf_port.hpp |
| QF/C++ port for QK kernel, Generic C++ compiler. | |
| file | qv/qf_port.hpp |
| QF/C++ port for QV kernel, Generic C++ compiler. | |
| file | qxk/qf_port.hpp |
| QF/C++ port to PC-Lint-Plus, Generic C++ compiler. | |
Preemptive Run-To-Completion (Non-Blocking) Kernel.
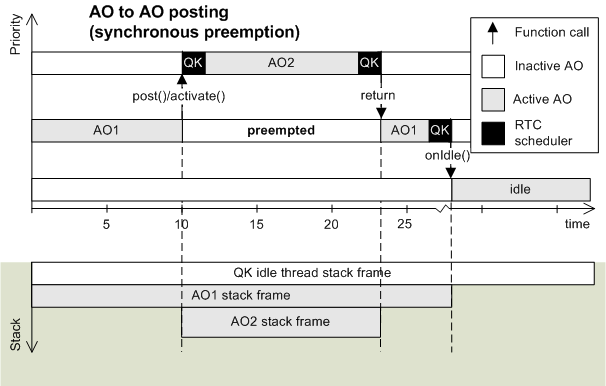
The preemptive, non-blocking QK kernel is specifically designed to execute non-blocking active objects (see also [PSiCC2, Chapter 10]). QK runs active objects in the same way as prioritized interrupt controller (such as NVIC in ARM Cortex-M) runs interrupts using single stack. Active objects process their events in run-to-completion (RTC) fashion and remove themselves from the call stack, the same way as nested interrupts remove themselves from the stack upon completion. At the same time high-priority active objects can preempt lower-priority active objects, just like interrupts can preempt each other under a prioritized interrupt controller. QK meets all the requirement of the Rate Monotonic Scheduling (a.k.a. Rate Monotonic Analysis RMA) and can be used in hard real-time systems.
The preemptive, run-to-completion (RTC) QK kernel breaks entirely with the endless-loop structure of the thread routines and instead uses threads structured as one-shot, discrete, run-to-completion functions, very much like ISRs [PSiCC2, Chapter 10]. In fact, the QK kernel views interrupts very much like threads of a “super-high” priority, except that interrupts are prioritized in hardware by the interrupt controller, whereas threads are prioritized in software by the RTC kernel.
As a fully preemptive multithreading kernel, QK must ensure that at all times the CPU executes the highest-priority thread (active object) that is ready to run. Fortunately, only two scenarios can lead to readying a higher-priority thread:
NOTE: The stack usage shown in the bottom panel displays stack growing down (towards lower addresses), as it is the case in ARM Cortex-M.
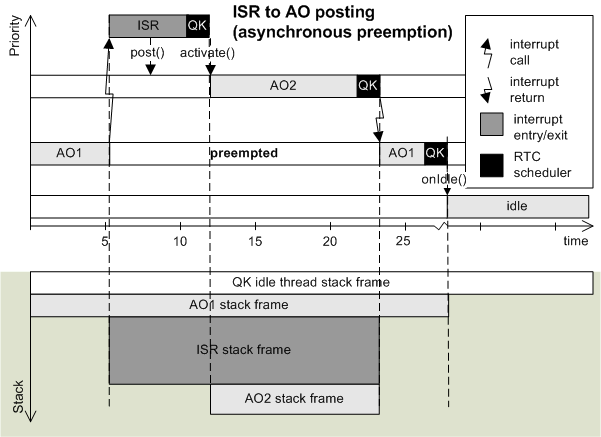
NOTE: The stack usage during asynchronous preemption on ARM Cortex-M is slightly simplified in the diagram below. A more detailed stack usage diagram is discussed later in the section explaining the "Detailed stack allocation in QK for ARM Cortex-M".
Next: QXK